🔒 Important Message: Concerns about data privacy and sensitive client information prevent the dataset's features, attributes, and records from being displayed. The offered sample code is only intended for your comprehension and familiarity.
IntelliBot: AI-Powered Q&A Solution for Enhanced Customer Support
Completed on 10-10-2023

Problem Statement
As part of this project, we built an AI driven chatbot that makes use of a Large Language Model (LLM), a vector database, and sophisticated embedding techniques. It designed to improve the caliber and efficiency of customer care by offering users of telecom routers and switching equipment exact, real-time assistance.
Tech Stacks
Python
LLM
Word Embedding
Fine Tuning
Vector DB
Flask
GIT
Pickle
Technologies listed above were utilized to implement the solutions for this project.
Sources of Data
Internal Data
Databases
Explain the Dataset
This project is based on multiple PDF files that has in depths information about the products and an excel sheet regarding one of the devices with two types of problems solutions. We are now leveraging this data to build a responsive solutions model in the form of chatbot, using Large Language Model(LLM) and advanced embeddings unrelated. For this, the chatbot is designed in a way to help users of telecom routers and switching equipment as suggested by them which ensures that customer care experience goes smooth and positive.
Workflow Architecture
These steps are involved in developing and implementing this project are described in the architecture below.
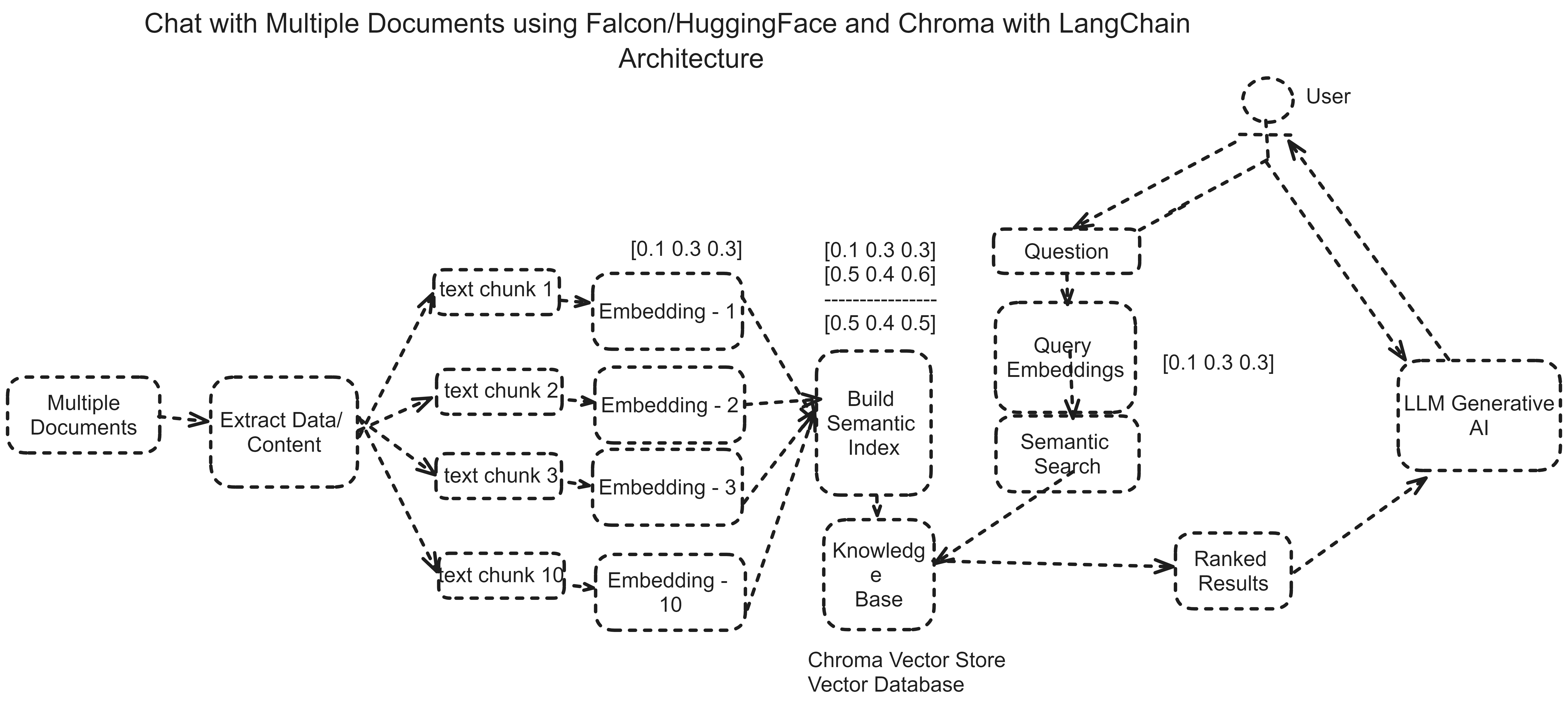
Sample Code Snippets
# app.py
from flask import Flask, request, jsonify
import chromadb
from chromadb.config import Settings
import torch
from transformers import AutoModelForSequenceClassification
from sentence_transformers import SentenceTransformer
app = Flask(__name__)
# Load model, tokenizer, and embedding model
model = AutoModelForSequenceClassification.from_pretrained('./saved_model')
embedding_model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Initialize Chroma DB
chroma_client = chromadb.Client(Settings(chroma_api_impl='chromadb.impl.sqlite.SQLiteAPI'))
collection = chroma_client.get_collection('telecom_support')
def get_prediction(text):
# Encode the text using the embedding model
embedding = embedding_model.encode(text, convert_to_tensor=True).numpy()
# Query Chroma DB
results = collection.query(embedding=embedding)
# Retrieve the top result
top_result = results[0]
# Predict using the Falcon model
inputs = torch.tensor([embedding])
outputs = model(inputs)
prediction = torch.argmax(outputs.logits, dim=1)
return top_result['metadata']['label']
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
text = data['text']
prediction = get_prediction(text)
return jsonify({'prediction': prediction})
if __name__ == '__main__':
app.run(debug=True)